Hetzner и замена диска

Начала у меня на одном из серверов Hetzner-а сыпаться база. Я не придал этому особого значения, восстановил её и продолжил работу, однако на следующий день история повторилась..
Тогда я решил проверить нет ли проблем с винтом, первое на что я решил глянуть был рейд массив:
|
1 2 3 |
#cat /proc/mdstat |
Тут я увидел, что один из дисков вылетел:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
root@server:~# cat /proc/mdstat Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md3 : active raid1 sda4[0] sdb4[1](F) 1822442815 blocks super 1.2 [2/1] [U_] md2 : active raid1 sda3[0] sdb3[1](F) 1073740664 blocks super 1.2 [2/1] [U_] md1 : active raid1 sda2[0] sdb2[1](F) 524276 blocks super 1.2 [2/1] [U_] md0 : active raid1 sda1[0] sdb1[1](F) 33553336 blocks super 1.2 [2/1] [U_] unused devices: <none> |
Далее, поняв суть проблемы, мне нужно было обратиться к тех.поддержке с просьбой о замене. Но прежде я сделал бэкапы базы, файлов и конфигураций.
После того как бэкап был готов, я написал в тех. поддержку. Для таких случаев (замена дисков) есть специальная форма в административной панели Robot. Находится она тут:
Support>Request>Server>Server problems>Hard drive is broken
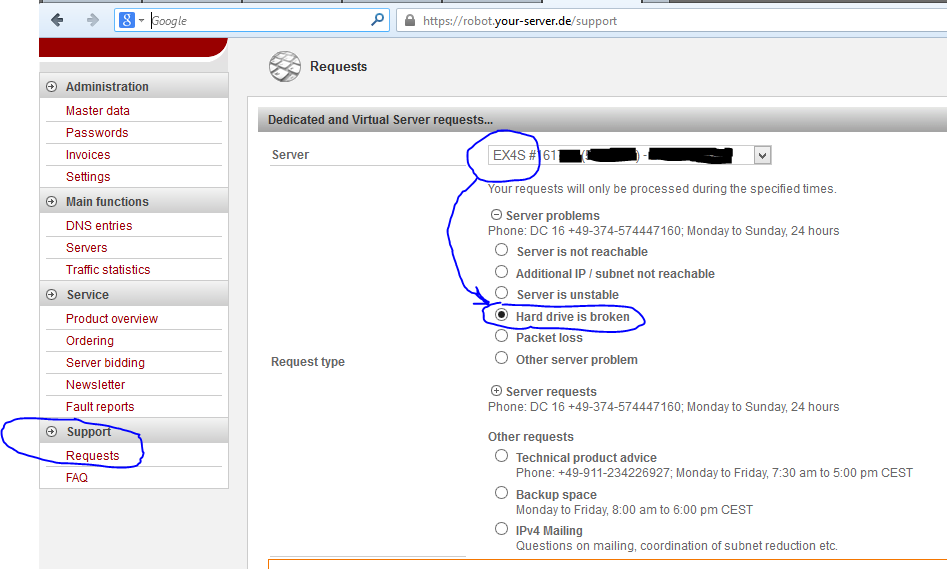
Hetzner Robot - Форма замены жесткого диска
Далее Вы увидите такую форму:
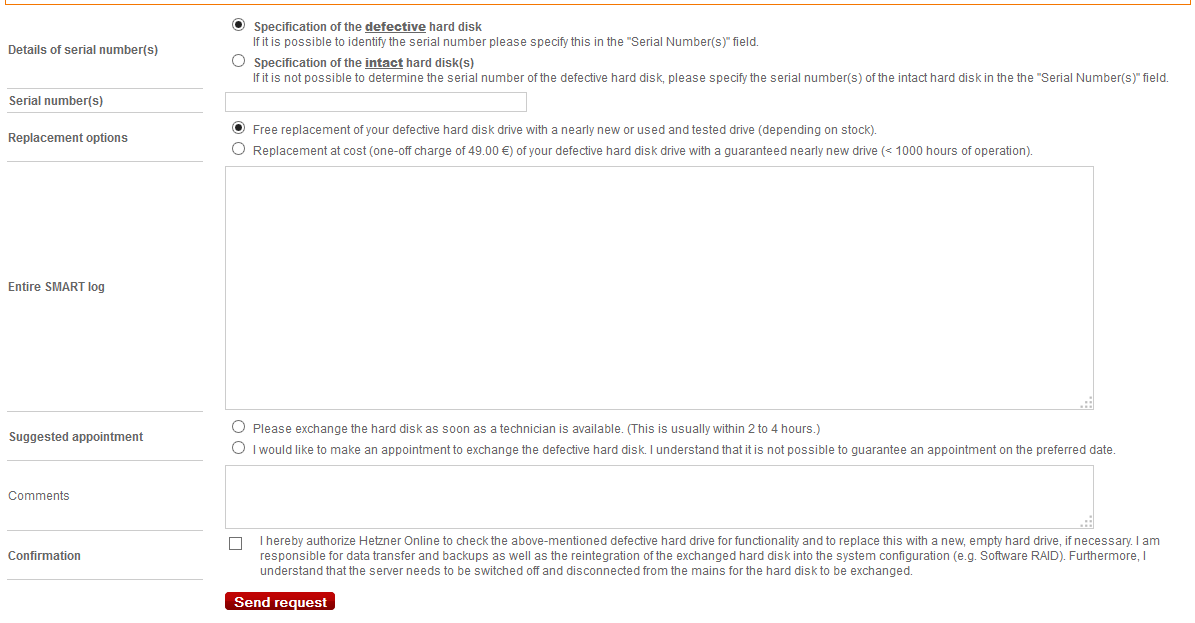
Hetzner форма замены жесткого диска
Вас попросят ввести серийный номер диска и информация от утилиты smartctl, так же предоставят мануалы как это сделать:
- Instructions on establishing the serial numbers as well as information on defective hard disks
- Instructions on exchanging a hard disk with Software RAID
- Instructions on creating a complete SMART log
Номер жесткого диска я получил выполнив команду (разумеется вам нужно указать вылетевший диск вместо sdb):
|
1 2 3 |
# /sbin/udevadm info --query=property --name=sdb | grep ID_SERIAL |
Результат:
|
1 2 3 4 |
ID_SERIAL=ST3000DM001-9YN166_S1F0A012 ID_SERIAL_SHORT=S1F0A012 |
Из этого вывода, нас интересует полный ID_SERIAL, т.е.
|
1 2 3 |
ST3000DM001-9YN166_S1F0A012 |
Далее необходимо выбрать тип замены: бесплатно, но при этом могут поставить б/у диск, либо 49 евро и поставят новый. Я согласился на вариант без дополнительных затрат.
Следующим шагом, нужно ввести информацию из smartctl. У меня такой утилиты не было установлено, поэтому пришлось поставить пакет smartmontools:
|
1 2 3 |
# apt-get install smartmontools |
После этого я выполнил необходимую команду:
|
1 2 3 |
#smartctl -x /dev/sdb |
На что получил ошибку от утилиты:
|
1 2 3 4 5 6 7 8 9 10 11 |
# smartctl -x /dev/sdb smartctl 5.40 2010-07-12 r3124 [x86_64-unknown-linux-gnu] (local build) Copyright (C) 2002-10 by Bruce Allen, http://smartmontools.sourceforge.net Device: /1:0:0:0 Version: scsiModePageOffset: response length too short, resp_len=47 offset=50 bd_len=46 >> Terminate command early due to bad response to IEC mode page A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options. |
Тут должна выдаться простыня инфы о диске, но в моем случае написали, что не может прочитать её. Это я и скопировал в форму.
Далее нас спрашивают хотим мы заменить диск сразу как только представится возможность, либо нас сначала надо уведомить. Тут основная фишка в том, что во время замены, сервер будет недоступен 2-4 часа. Я инфу всю забэкапил, поэтому выбрал первый вариант, а именно чтобы заменили тогда, когда им будет удобно.
На последнем этапе подтвердил галочкой что они могут чинить там все, и что с рисками я ознакомлен. И отправил запрос.
Спустя два часа, мне пришел ответ:
|
1 2 3 4 5 |
Dear Client, As requested we have replaced the broken hard disc on your server. |
Диск заменили, я зашел на сервер, и увидел что диск поменяли на новый, т.е. у него в S.M.A.R.T. было около часа или двух работы.
Следующим этапом стало добавление диска в рейд. Все этапы подробно описаны тут: Замена жесткого диска
Выполнив эти этапы я перезагрузился, и увидел что пошла синхронизация данных, посмотреть ход работы, можно командой:
|
1 2 3 |
#cat /proc/mdstat |
Т.к. сервер во время синхронизации данных активно работал, то копирование терабайтных разделов заняло несколько дней.
добавлено: 25.03.2015
Обратите внимание, что скорость синхронизации можно регулировать. Если вы отключили все сервисы и можете выкрутить скорость синхронизации на максимум, тогда делаете следующее:
1) Выполняем вот эти команды, и запоминаете значения которые установлены:
должны вывести что-то типа 1000 и 100000
2) Меняете эти значения, например на 250000 и 500000 соответственно:
3) Дожидаетесь конца синхронизации, и восстанавливаете их обратно:
Подробнее про это написано тут: 5 Tips To Speed Up Linux Software Raid Rebuilding And Re-syncing
Но на этом все не закончилось, один из дисков, никак не хотел синхронизироваться, это можно заметить увидев рядом с разделом флаг (S), что означает Spare:
|
1 2 3 4 5 6 7 8 9 10 11 |
Personalities: [raid1] md0: active raid1 sda1[2] sdb1[1] 33553336 blocks super 1.0 [2/2] [UU] md1: active raid1 sda2[2] sdb2[1] 524276 blocks super 1.0 [2/2] [UU] md2: active raid1 sda3[2](S) sdb3[0] 2110014324 blocks super 1.0 [2/1] [U_] |
Я попробовал перезагрузиться, и процесс синхронизации пошел снова, однако подождав еще пару дней, я получил тот же самый результат.
Погуглив немного, я не нашел четкого решения, однако люди писали, что такая проблема, может быть из-за того, что сыпется основной диск (диск с которого происходит синхронизация). Я подумал, что это вполне может быть, и заглянул dmesg:
|
1 2 3 |
#dmesg |
В результатах которые выдала мне команда, я увидел, что действительно есть проблемы с не читаемыми секторами на диске sda.Ошибки выглядят примерно так (картинка с askubuntu):
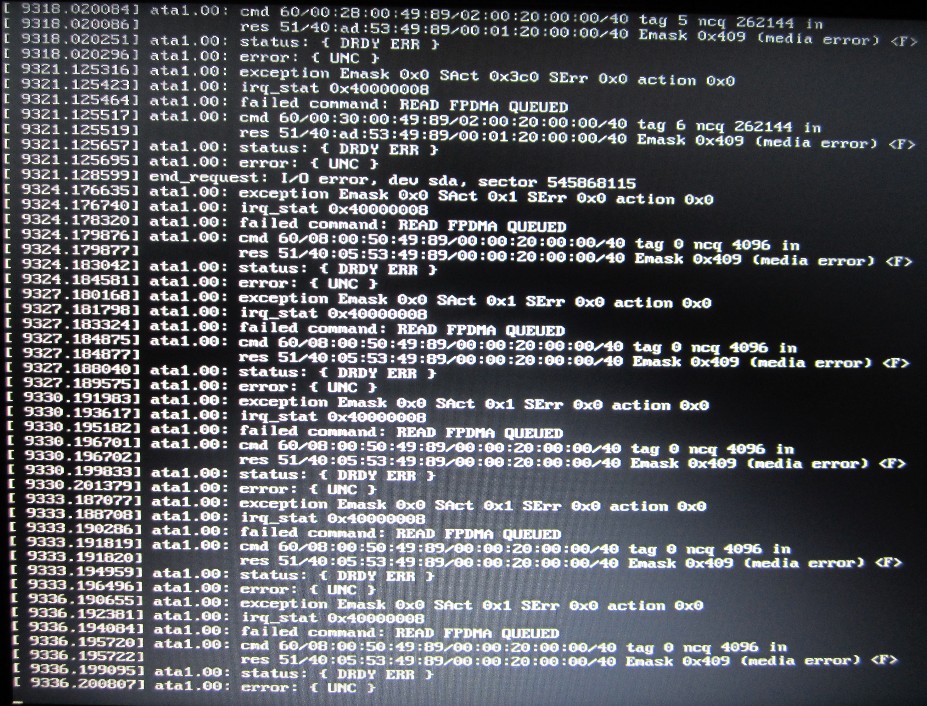
Dmesg. Сыпется диск.
Соответственно, mdadm ловя эти ошибки, просто не может синхронизировать диски. Рецепта что дальше делать я не нашел, говорили о том, чтобы копировать данные, менять диск, но в таком бы случае пришлось бы устанавливать систему с нуля, а такая перспектива меня не радовала..
Я решил попробовать, "восстановить" диск с помощью утилиты e2fsck, которая может помечать битые сектора, чтобы их в дальнейшем не использовали. Т.к. диск sda был системный, то я не мог запустить восстановление, пока он активен. В обычной жизни, я бы загрузился с Live CD, однако сейчас сервер стоял в Германии, а я находился в Украине..
Но, Hetzner-ы молодцы и предусмотрели такие ситуации, сделав возможность загрузиться с Rescue системы. Для того чтобы запустить её, идем в панель Robot, в такой раздел:
Main functions>Servers>Нужный сервер>Вкладка Rescue
Далее выбираем архитектуру, в моем случае это 64 bit. Если вы не знаете какая у вас, то зайдите на сервер и выполните команду:
|
1 2 3 |
#arch |
В ответ получите что-то вроде:
|
1 2 3 |
x86_64 |
Далее Вам нужно нажать кнопку: [Activate Rescue System]
Разумеется во время работы Rescue системы, ваш веб-сервер будет недоступен, поэтому если есть критические сайты, лучше их на время куда-нибудь перенести заранее, чтобы они могли работать. На восстановление может потребоваться значительное время. В моем случае, это заняло около 6-8 часов.
На следующем шаге Вам выдадут root пароль, с помощью которого Вы и сможете подключиться к Rescue системе. Но перед этим нужно, перезагрузить сервер. Для этого логинимся на сервер со старой учеткой, и перезагружаем его командой:
|
1 2 3 |
#reboot |
После этого, конектимся по SSH к нашему серверу, с такими учетными данными:
- ip: ip вашего сервера
- порт: 22
- логин: root
- пароль: пароль выданный после активации Rescue System
Далее я запустил проверку диска вот так:
|
1 2 3 |
#e2fsck -f -c -v -y /dev/md2 |
Тут я указал, чтобы диск проверили в read-only режиме, и битые сектора пофиксили. Мануал по параметрам можно посмотреть тут: e2fsck(8) - Linux man page.
Выполнения команды пришлось подождать, по завершению, я увидел что нашлось штук 30 "плохих" блоков и они были "исправлены".
Далее я посмотрел прогресс синхронизации дисков, который сам автоматически запустился после загрузки Rescue системы:
|
1 2 3 |
#cat /proc/mdstat |
Я увидел, что синхронизация идет на скорости 160 мбайт/сек, что было намного быстрее чем когда система загружена в обычном режиме, но самое главное до завершения осталось около часа. Я не стал спешить, а дождался завершения. На этот раз, Spare флаг исчез, а диски синхронизировались. Я снова перезагрузился, командой reboot и теперь загрузилась уже не Rescue, а моя система в обычном режиме.
Как всегда у меня - все заканчивается победой, чего и Вам желаю!
--[10.08.13]--
Где-то через пару недель, сдох полностью и первый винт (/dev/sda), благо я успел синхронизироваться с новым. Поэтому если у вас начались проблемы с битыми секторами, делайте бэкап важных данных как можно быстрее!
--[14.05.14]--
Где-то неделю назад, со мной списался Григорий Р. у него было несколько вопросов, на которые я попытался ему ответить. Удалось мне помочь ему информацией или нет, судить не могу. Однако, знаю что у него все сложилось замечательно - ему так же удалось заменить диск и синхронизировать его.
В нашем диалоге, мы затронули один интересный вопрос о котором я бы хотел рассказать, а именно время синхронизации. Я предположил что его можно вычислить таким способом:
Попробуй запусти копирование большого файла сейчас (10-20 Гб), на работающей системе, с нормального винта на него же. Дальше посмотри скорость копирования. И посчитай, сколько займет копирование всего винта. Добавь какой-нибудь запас, это и будет примерное время.
Как-то так:
скорость копирования файла = 50 МБайт/с
2ТБ = 2000 Гб = 2.000.000 МБ
2.000.000 / 50 = 40.000 сек
40.000 сек / 60 / 60 = 11 часов
11 * 1,5(запас) = 16 часов
По сути, в момент синхронизации происходит копирование раздела 1 в 1 + некоторые доп. операции. Так что, думаю, такой расчет вполне корректен.
После этого Григорий сделал у себя тест и получил такой результат:
Вот такие данные у меня получились:
~ # dd if=/dev/zero of=/tmp/test.txt
^C2360935+0 records in
2360935+0 records out
1208798720 bytes (1.2 GB) copied, 3.40306 s, 355 MB/s2.000.000 / 355 = 5,633 сек
5,633 / 60 / 60 = 1,5 часа
1,5 * 1,5 = 3 часа
Я его попросил скинуть мне реальные данные, когда диск будет синхронизироваться. Сегодня он их мне прислал, за что ему огромное спасибо!!! Итак данные о синхронизации:
Personalities : [raid1]
md3 : active raid1 sdb4[2] sda4[0]
1822312704 blocks super 1.2 [2/1] [U_]
resync=DELAYEDmd2 : active raid1 sdb3[2] sda3[0]
1073610560 blocks super 1.2 [2/1] [U_]
[>....................] recovery = 1.0% (11589248/1073610560) finish=113.3min speed=156200K/sec
и еще один замер, для винта побольше:
3 террабайтный винт добавлялся в рейд 8,5 часов суммарно на /, /home, /boot и swapВсе это время нельзя было включать виртуальные машины, они очень сильно влияли на время ребилда
Как видим, теория +/- подтверждается. Соответственно, если Вас интересует время синхронизации, можете попробовать его прикинуть таким же образом как это сделали мы.
В остальном, желаю Вам использовать эту статью только в образовательных целях и никогда не сталкиваться с умирающими винтами 🙂
--[Добавлено 02.03.2014]--
Еще один читатель прислал информацию для статистики:
Filesystem: /dev/md3
Size: 1.7T
Used: 23G
Avail: 1.6T
Use%: 2%
Mounted on: /home
и статистика mdadm:
md3 : active raid1 sda4[0] sdb4[1]
1839220031 blocks super 1.2 [2/2] [UU]
[>....................] resync = 2.9% (54763968/1839220031) finish=573.5min speed=51849K/sec
Author: | Rating: / | Tags:

5 comments.
Write a comment