Raid 1 в Ubuntu из новых дисков

При загрузке компьютера BIOS заботливо сообщил что на одном из дисков у меня начались проблемы. При ближайшем осмотре оказалось что на нем начали появляться перемещенные сектора, и при лимите для нотификаций в 5 у меня их было уже больше 2000. Означало это, что одному из дисков начал приходить конец..
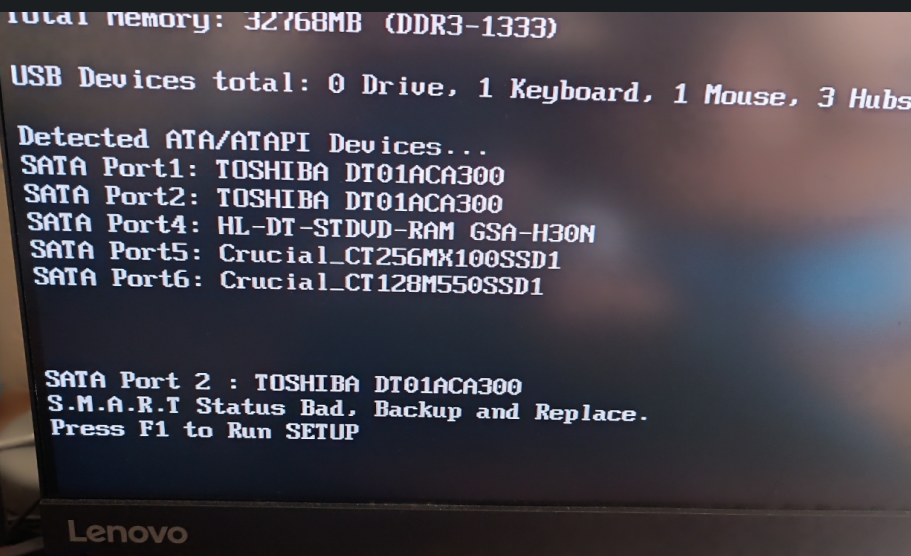
Модель умирающего диска Toshiba DT01ACA300 (3 TB) и отработал он без малого 25.500 часов, что при работе по 8-10 часов в день составляет ~7 лет. Для "домашнего" диска вполне себе прекрасный результат. Более того, данный диск был частью Raid 1, что означало что его довольно просто заменить на аналогичный, сделать снхронизацию и жить дальше.

Посмотрев на цены и немного подумав, я решил, что пожалуй второй диск всего скорее тоже рано или поздно начнет отказывать (тк покупал оба в одно время), и менять только один нет смысла. Решил купить новые, большего объема. Почитав отзывы и сопоставив цены купил Seagate Exos 7E8 (8TB) ST8000NM000A .
Как я выбирал диск
Тут можно долго дискутировать, но мой критерий выбора был: объем + характеристики + цена + отзывы.
С объемом понятно, чем больше тем лучше. Объем напрямую влияет на цену. Отзывы тоже понятно. Остановлюсь на характеристиках.
Основных характеристик несколько: скорость вращения, тип записи. Инфу можно найти на сайте производителя, в частности вот спека по моему диску.
- Модельный объем: 8 Тб
- Тип записи: CMR
- Скорость вращения: 7200 rpm
- Скорость чтения: до 250 МБ/с
- 2 млн часов работы
Я не буду вдаваться в подробности, но советую погуглилть и почитать чем отличается тип записи CMR от SMR и какие есть недостатки и преимущества. Я искал именно CMR. Если не можете найти тип у выбранного вами диска, то попробуйте поискать по serial number по следующей ссылке:
- https://nascompares.com/answer/list-of-wd-cmr-and-smr-hard-drives-hdd/
Нашел на амазоне, цена была 145 euro.
Поле того как диски прибыли я их установил и осталось только мигрировать данные.
Настройка нового Raid 1. Как делать НЕ надо.
В моем текущей конфигурации, все порты сата заняты. В связи с этим, мой план был следующий: вытаскиваю диски из системника, вставляю новые на их места. Создаю новый рейд. Временно убираю один из других дисков и на его место вставляю один из старых, монтирую его и копирую с него данные в новый рейд.
План казался довольно простой, плюс бекап данных не был проблемой, тк в теории старые данные все еще можно было вытянуть с любого из старых дисков.
Теория, теорией, но я решил сперва эту гипотезу проверить. А проверить я решил так: помечаю "хороший" диск из рейда как сбойный, убираю его из рейда, монтирую в другую папку и убеждаюсь, что могу там увидеть данные. Немного погуглив, я даже нашел похожий кейс вот тут
- https://askubuntu.com/questions/684453/remove-mdadm-raid1-without-loosing-data
Я отмонтировал рейд массив
|
1 2 3 |
# umount /dev/md0 |
затем пометил "хороший" диск как сбойный
|
1 2 3 4 |
# mdadm --fail /dev/md0 /dev/sda1 mdadm: set /dev/sda1 faulty in /dev/md0 |
и удалил его из массива
|
1 2 3 4 |
# mdadm --remove /dev/md0 /dev/sda1 mdadm: hot removed /dev/sda1 from /dev/md0 |
далее я попробовал примонтировать его, но получил ошибку
|
1 2 3 4 5 |
# mount -t auto /dev/sda1 /mnt/disk_a mount: /mnt/disk_a: unknown filesystem type 'linux_raid_member'. dmesg(1) may have more information after failed mount system call. |
Далее, осознав что примонтировать не получится, я попробовал вернуть диск в массив. Ведь в моем понимании данные должны были сохраниться идентичными.
К сожалению, теми способами которые я попробовал, я не смог этого добиться
|
1 2 3 4 5 6 7 8 |
# mdadm --assemble --force /dev/md0 /dev/sda1 mdadm: Found some drive for an array that is already active: /dev/md/0 mdadm: giving up. # mdadm --manage /dev/md0 --re-add /dev/sda1 mdadm: --re-add for /dev/sda1 to /dev/md0 is not possible |
В конечном итоге, я вернул диск обратно, вот так
|
1 2 3 4 5 6 7 8 9 10 |
# mdadm --manage /dev/md0 --add /dev/sda1 mdadm: added /dev/sda1 # cat /proc/mdstat Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10] md0 : active raid1 sda1[2] sdb1[1] 2930133824 blocks super 1.2 [2/1] [_U] [>....................] recovery = 0.1% (4345216/2930133824) finish=546.8min speed=107509K/sec |
но это привело к синхронизации данных, которая заняла 10+ часов с выходящего из строя диска. Мне повезло и все закончилось хорошо.
Я предполагаю, что можно было монтировать диск не напрямую, а создать новый рейд из него, типа /dev/md1 и тогда бы все заработало, но наткнулся на описание этого процесса вот тут
- https://myrtana.sk/articles/how-to-modify-existing-software-raid1-md
И решил, что остановлюсь на этапе мема из этой статьи

Я решил больше не рисковать. Не хватало экспертизы в данной задумке, да и не было время на эксперименты.
Оставалось еще два варианта синхронизации
- Вариант 1. Длинный. Не проверенный.
- Убираем один "старый" диск из рейда.
- Подкидываем "новый" диск
- Ждем 8-10 часов пока синканутся данные
- Убираем второй "старый" диск из рейда
- Ждем 8-10 часов пока синканутся данные
- Далее с помощью бубна, гугла и магии, расширяем рейд до нового размера дисков
- Тут описан процесс, если у Вас бубен уже есть
- https://4admin.info/replacing-disks-mdadm-array-increasing-size-array/
- Вариант 2. Надо много места. Надежный
- Копируем все с рейда на сторонние диски
- Убираем старые диски и пока не трогаем их (чтоб в случае чего восстановить старый рейд)
- Подкидываем новые диски. Создаем спокойно новый рейд с нуля.
- Копируем старые данные со сторонних дисков обратно.
Я выбрал "Вариант 2", тк была возможность быстро разбросать данные по другим носителям.
Настройка нового Raid 1 с нуля
Cтавим mdadm
|
1 2 3 |
sudo apt-get install mdadm |
У меня уже он был установлен, поэтому я пропустил этот шаг.
Тк диски у меня пустые и одинаковые, то следующим шагом можно находить имена устройств
|
1 2 3 |
sudo fdisk -l |
и сразу собирать вот такой командой
|
1 2 3 |
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda /dev/sdb |
Но, я бы рекомендовал пойти другим путем, а именно создать разделы немного меньшего размера, и после этого собирать рейд из разделов. Причина этого в том, что если в будущем один из дисков вылетит и мы захотим заменить его на диск другого производителя такого же объема, то есть вероятность того, что доступный объем будет отличаться, что приведет к проблемам. Честно сказать, сам я не сталкивался с подобным, но такое утверждение распространено и звучит логично и убедительно.
Я не стал страдать с командной строкой и сдела все через KDE Partition Manager, где это занимаеn пару кликов.
Находим диск и жмем "New Partition Table"
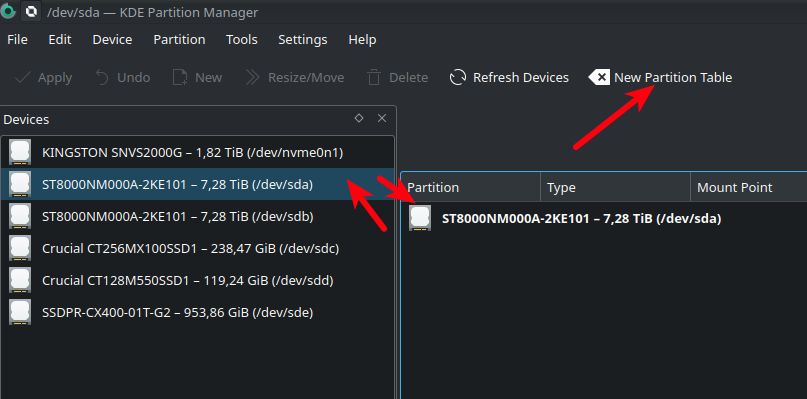
Выбираем GPT и [Create partition Table]
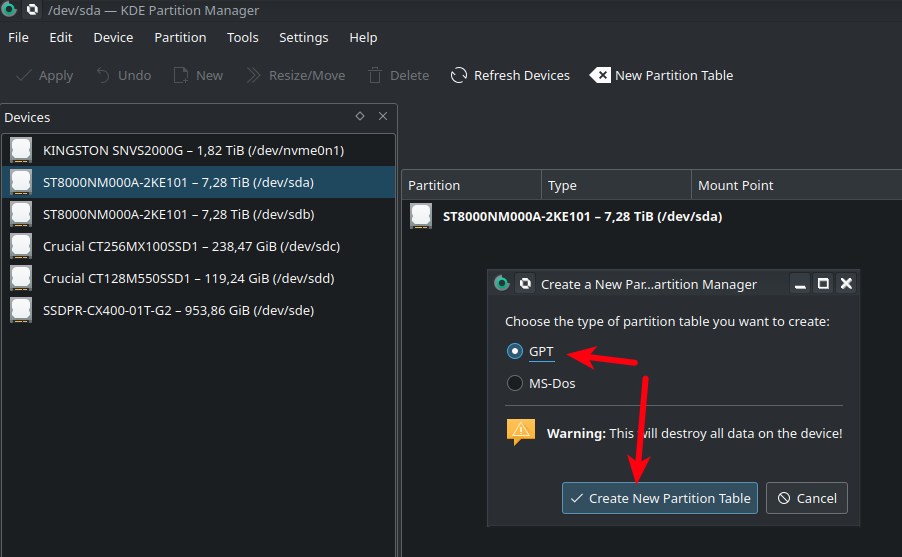
Получаем диск с таблицей разделов
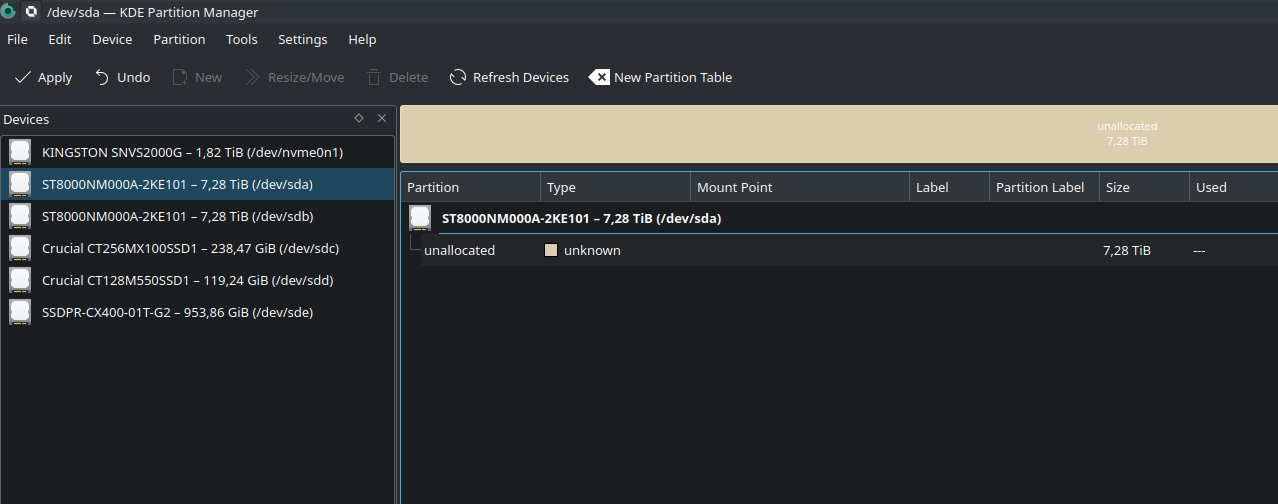
Как видно диск у меня 7,28 ТБ, хотя маркетинговая цифра у диска 8 TB. Куда же делись (8 - 7,28) * 1024 = 737 Гб? Дело в том, что "8000.." это цифра в байтах, ну а кыждый следующий порядок объема измеряется измеряется не в 1000 значений, а в 1024. Вот и получается
|
1 2 3 4 |
8 . 000.000.000.000 /1024/1024/1024/1024 = 7.275957 TB GB MB KB Byte |
Вот и получается 7,28. Но, как я писал выше эти 7.28 получаются округлением десятков
|
1 2 3 |
7,2759 => 7,276 => 7.28 |
а это значит, что неплохо оставить небольшой запас. Кто-то рекомендует 10 мб, кто-то 100 мб. Я не жадный и диск, всего скорее, не заполнится до следующей замены на 100%, поэтому оставлю побольше. Итак, выбираем неразмеченную область и жмемь [New]
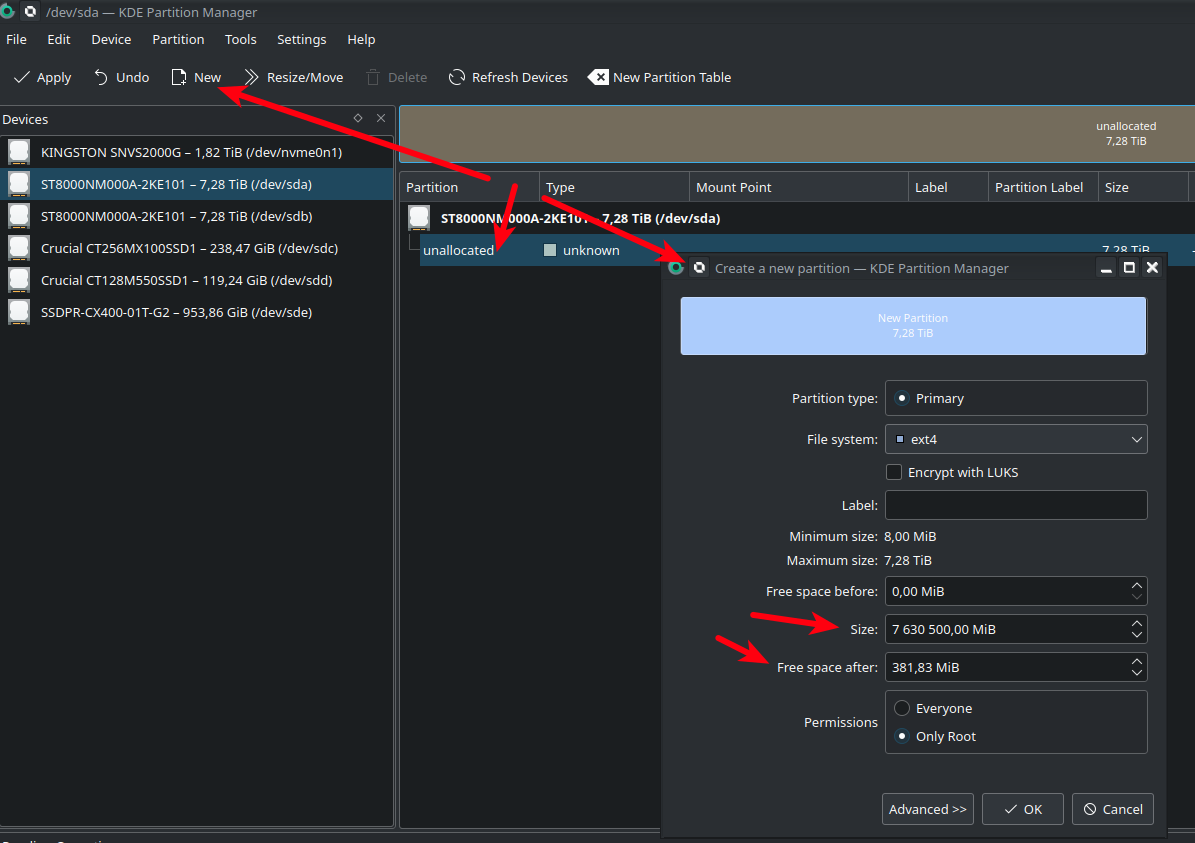
Я выровнял размер раздела до 7.630.500 мб, оставив 381.83 Мб, как резерв на случай замены диска при выходе из строя на диск другого производителя.
(!) В качестве файловой системы я по привычке выбрал ext4, но тк она перезатрется при создании рейда, думаю, это не имеет значения, те можно выбрать unformatted
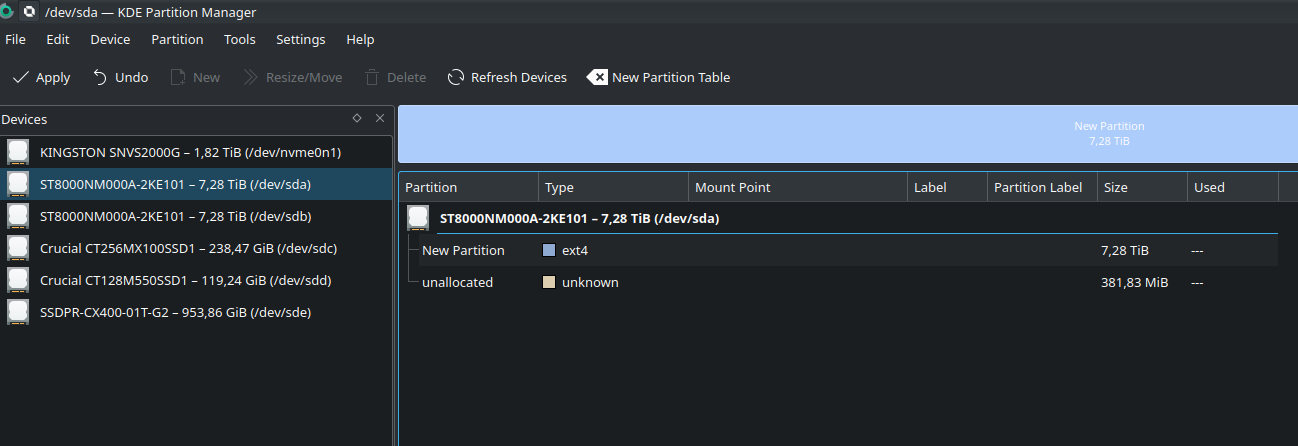
Теперь тоже самое проделываю с другим диском, указывая тот же размер и жмем [Apply]. Ожидаем пока операции закончатся
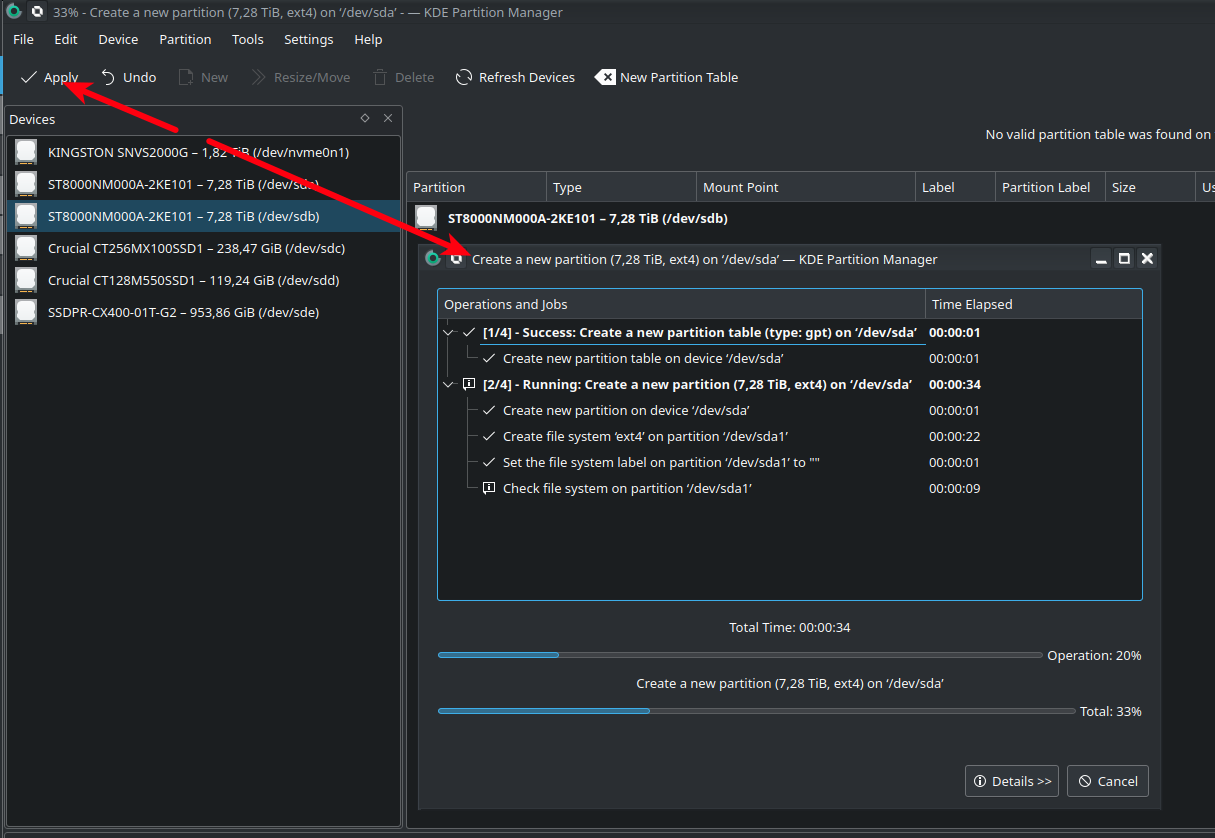
После окончания смотри как называются разделы, через (fdisk -l) или там же в KDE Partition Manager. У меня это /dev/sda1 и /dev/sdb1 соответственно
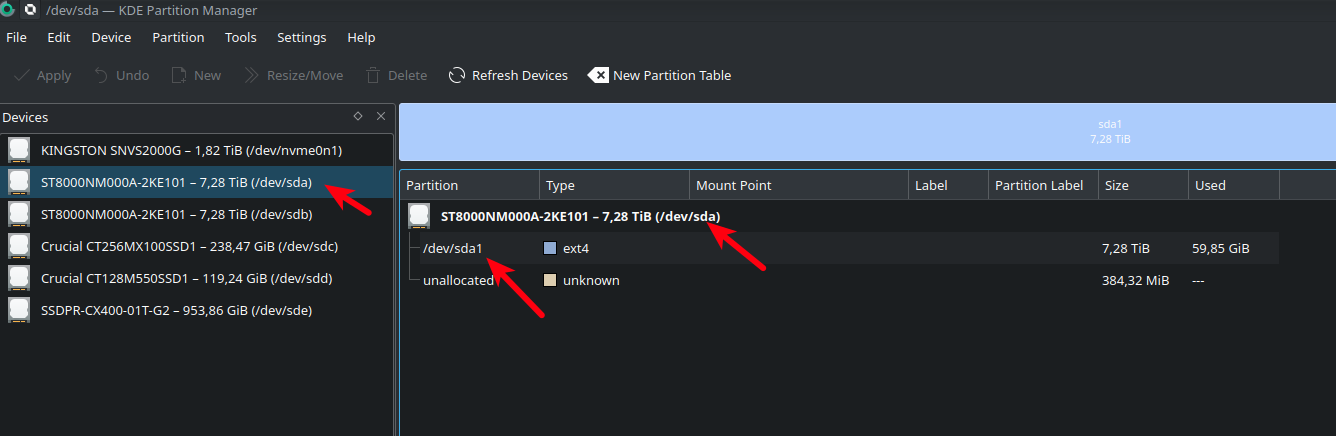
Теперь создаем Raid 1
|
1 2 3 |
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1 |
Нас попросят подтвердить операцию, после чего напишут что процесс создания начался
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1 mdadm: /dev/sda1 appears to contain an ext2fs file system size=7813632000K mtime=Thu Jan 1 01:00:00 1970 mdadm: Note: this array has metadata at the start and may not be suitable as a boot device. If you plan to store '/boot' on this device please ensure that your boot-loader understands md/v1.x metadata, or use --metadata=0.90 mdadm: /dev/sdb1 appears to contain an ext2fs file system size=7813632000K mtime=Thu Jan 1 01:00:00 1970 mdadm: size set to 7813499904K mdadm: automatically enabling write-intent bitmap on large array Continue creating array? Y mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started. |
Теперь надо "немного" подождать, в моем случае это 630 минут или около 10 часов 🙂 Узнать прогресс можно командой
|
1 2 3 4 5 6 7 8 9 10 11 |
$ sudo cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid1 sdb1[1] sda1[0] 7813499904 blocks super 1.2 [2/2] [UU] [>....................] resync = 0.1% (13843968/7813499904) finish=630.7min speed=242536K/sec bitmap: 59/59 pages [236KB], 65536KB chunk unused devices: <none> |
Если хотите наблюдать за процессом, можете использовать утилиту watch с кол-вом секунд через которые будет выведен апдейт, например 60 секунд
|
1 2 3 |
$ sudo watch -n60 cat /proc/mdstat |
Иногда бывает, что скорость синхронизации намеренно ограничена, проверить это можно в 2х следующих файлах, но нас интересует с постфиксом "_max"
|
1 2 3 4 5 6 7 |
# cat /proc/sys/dev/raid/speed_limit_max 100000 # cat /proc/sys/dev/raid/speed_limit_min 1000 |
изменить можно попросту записав новое значение в этот файл, например так лимит будет установлен в 500 Мб/с, что гораздо выше возможностей HDD
|
1 2 3 |
echo "500000" > /proc/sys/dev/raid/speed_limit_max |
В моем, да и в любом "домашнем" случае можно верхнее значение увеличить до максимума, чтобы снять ограничения. В промышленных системах, это используется для ограничения нагрузки на часть рейд массива с которой идет чтение, чтобы зависящие сервисы (например веб-сайты) продолжали работать.
Более расширенную иформацию можно получить вот так
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
$ sudo mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Tue Jul 25 19:29:05 2023 Raid Level : raid1 Array Size : 7813499904 (7.28 TiB 8.00 TB) Used Dev Size : 7813499904 (7.28 TiB 8.00 TB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Intent Bitmap : Internal Update Time : Tue Jul 25 19:44:04 2023 State : clean, resyncing Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Consistency Policy : bitmap Resync Status : 2% complete Name : homenet100:0 (local to host homenet100) UUID : 2664905c:2331ea6e:714243e0:9e4fa753 Events : 180 Number Major Minor RaidDevice State 0 8 1 0 active sync /dev/sda1 1 8 17 1 active sync /dev/sdb1 |
Тут тоже видим, что идет синхронизация и надо ждать "Resync Status : 2% complete"
После того как синхронизация будет завершена, нужно отформатировать массив, для этого выполняем
|
1 2 3 |
sudo mkfs.ext4 /dev/md0 |
Далее нужно сгенерировать и добавить конфиг в mdadm.conf чтобы в случае рассинхрона, диски автоматически синхронизировались.
Делаем бекап
|
1 2 3 |
sudo cp /etc/mdadm/mdadm.conf /etc/mdadm/mdadm.conf.bak |
Генерируем конфиг
|
1 2 3 4 5 6 |
$ sudo mdadm --detail --scan ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=homenet100:0 UUID=2664905c:2331ea6e:714243e0:9e4fa753 devices=/dev/sda1,/dev/sdb1 |
|
1 2 3 |
и получившуюся строку вставляем в файл конфига /etc/mdadm/mdadm.conf или одной командой
|
1 2 3 |
sudo mdadm --detail --scan --verbose | sudo tee -a /etc/mdadm/mdadm.conf |
Осталось создать точку монтирования и примонтировать туда новый диск. Обычно диски монтируют в папку/mnt/, но в моем случае мне удобнее примонтировать раздел в корень. Создаем папку
|
1 2 3 |
sudo mkdir /store |
далее берем UUID диска (обратите внимание, что это НЕ uuid из команды mdstat -D)
|
1 2 3 4 5 6 7 |
sudo file -s /dev/md0 /dev/md0: Linux rev 1.0 ext4 filesystem data, UUID=6f173a57-1845-47ca-95b7-8cc8d232f6f4 (extents) (64bit) (large files) (huge files) # так же можно использовать blkid sudo blkid /dev/md0 |
и добавляем его в fstab
|
1 2 3 4 5 6 |
$ sudo nano /etc/fstab # /dev/mdo => /store UUID=6f173a57-1845-47ca-95b7-8cc8d232f6f4 /store ext4 defaults 0 2 |
Перезагружаемся и проверяем.
Последним штрихом, даем права на запись на диск для текущего или всех пользователей. В моем случае, у меня одна учетка, поэтому достаточно сделать себя владельцем
|
1 2 3 4 |
$ sudo chown -R vo:vo /store $ chmod -R 0755 /store |
Теперь нужно только скопировать все файлы назад.
Выводы
- Бекап, бекап и еще раз бекап.
- Если вы придумали гениальный план по миграции, и даже нашли подтверждение в интернете, что он должен сработать, все равно сделайте в начале бекап.
- Если есть время и ресурсы, сделайте рейд из маленьких дисков (например на флешке разделы по 5мб) и проверьте как ваша теория будет работать.
- Если у вас такая же как ситуация с переездом на новые диски и есть свободные sata порты, то проще всего создать новый массив с нуля и скопировать данные со старого рейд массива напрямую. Если такой возможности нет, то разбросайте данные на другие носители (внешние жесткие диски, ноут, etc) и оставьте диски из оргинального рейда до полного восстановления данных на новый рейд с этих носителей.
Author: | Rating: / | Tags:

Leave a Reply